
Вы хотите сделать машинное обучение с помощью Python, но у вас возникли вопросы с чего начать? В этом уроке вы сделаете свой первый проект по машинному обучению с помощью Python. В уроке мы разберем шаг за шагом как:
- Скачать и установить Python SciPy и какие самые полезные пакеты для машинного обучения в Python.
- Загрузить датасет, поймем его структуру с помощью статистических методов и визуализируем данные
- Создадим 6 моделей машинного обучения, выберем лучшую и убедимся что точность модели является приемлемой
Если вы новичок в машинном обучении и хотите начать использовать Python, этот урок был разработан для вас.
Как начать использовать машинное обучение в Python?
Лучший способ научиться машинному обучению — проектировать и завершать небольшие проекты.
Python может быть пугающим при начале работы
Python является популярным и мощным интерпретируемым языком. В отличие от R, Python является и полным языком и платформой, которые можно использовать как для исследований, численных расчетов, так и для разработки производственных систем.
В Python есть также много модулей и библиотек на выбор, обеспечивая несколько способов выполнения каждой задачи.
Лучший способ начать использовать Python для машинного обучения — это разобрать готовый проект по машинному обучению и затем его сделать самому с нуля:
- Это заставит вас установить и запустить Python интерпретатор.
- Это даст вам понимание с высоты птичьего полета о том, как выглядит небольшой проект.
- Это даст вам уверенность, чтобы перейти к собственным задача и проектам.
Новичкам нужен небольшой сквозной проект
Книги и курсы порой часто расстраивают. Они дают вам много теоретических конструкций и фрагментов, но вы никогда не увидите, как все они сочетаются друг с другом.
Когда вы применяете машинное обучение к собственному датасету, вы работаете над проектом. Проект по машинному обучению может быть не всегда последовательным, но обычно он имеет несколько выраженных этапов:
- Постановка задачи
- Подготовка данных
- Оценка качества алгоритмов
- Оптимизация результата
- Презентация результата.
Лучший способ по-настоящему примириться с новой платформой или инструментом – это работать над проектом машинного обучения и покрыть эти ключевые этапы.
Если вы можете сделать это, у вас будет шаблон, который можно будет использовать в будущем на другой выборке данных или задаче. Вы сможете заполнить пробелы, такие как дальнейшая подготовка данных и улучшение алгоритмов.
"Hello World!" машинного обучения
Отличным примером небольшого проекта чтобы начать является задача классификация цветов (на примере цветов ириса).
Это хороший проект, потому что он легко интерпретируется.
- Атрибуты данных являются числовыми, так что вы должны разобраться, как загрузить и обрабатывать данные
- Это проблема классификации, позволяющая практиковаться с, возможно, более простым типом контролируемого алгоритма обучения
- Задача является многоклассовой классификацией и может потребовать некоторой специализированной обработки
- Выборка имеет только 4 атрибута и 150 строк, что означает, что она достаточно мала, легко будет обработана в операционном памяти локальном компьютера (и легко визуализировать на экране)
- Все числовые атрибуты находятся в одном и том же масштабе и одинаковой шкале, не требуя специальной нормализации или масштабирования для начала работы
Давайте начнем проект "hello world" машинного обучения в Python.
Машинное обучение в Python (начало проекта)
Вот краткий обзор того, что мы собираемся охватить:
- Установка платформы Python и SciPy
- Загрузка датасета
- Анализ датасета
- Визуализация данных
- Оценка алгоритмов машинного обучения
- Прогнозирование данных
Не торопитесь, проработайте и поймете, что происходит на каждом шагу. Мы рекомендуем самостоятельно вводить команды.
Если у вас есть какие-либо вопросы, пожалуйста, задавайте их в чат.
1. Загрузка, установка и запуск Python и SciPy
Раздел для тех, у кого ее не установлен Python и SciPy. Мы не будем подробно останавливаться на том как устанавливать Python, есть много пошаговых руководств в интернете как это сделать или рекомендуем посетить раздел "Введение в Python".
1.1 Установка библиотек SciPy
Есть 5 ключевых библиотек, которые необходимо установить. Ниже приведен список библиотек Python SciPy, необходимых для этого руководства:
- scipy
- numpy
- matlibplot
- pandas
- sklearn
На сайте SciPy есть отличная инструкция по установке вышеуказанных библиотек на ключевых платформах: Windows, Linux, OS X mac. Если у вас есть какие-либо сомнения или вопросы, обратитесь к этому руководству, через него прошли миллионы людей.
Существует множество способов установить библиотеки. В качестве совета мы рекомендуем выбрать один метод и быть последовательным в установке каждой библиотеки. Если вы пользуетесь Windows или вы не уверены как это сделать, мы рекомендую установить бесплатную версию Anaconda, которая включает в себя все, что вам нужно (windows, macOS, Linux).
1.2 Запуск Python и проверка версий
Рекомендуется убедиться, что среда Python была успешно установлена и работает в штатном состоянии. Сценарий ниже поможет вам проверить вашу среду. Он импортирует каждую библиотеку, требуемую в этом учебнике, и печатает версию.
Откройте командную строку и запустите Python:
pythonМы рекомендуем работать непосредственно в интерпретаторе или писать скрипты и запускать их в командной строке, нежели редакторах и IDEs. Это позволит сосредоточиться на машинном обучении, а не инструментарии программиста.
Введите или скопируйте и вставьте следующий скрипт в интерпретатор:
# Проерка версий библиотек
# Версия Python
import sys
print('Python: {}'.format(sys.version))
# Загрузка scipy
import scipy
print('scipy: {}'.format(scipy.__version__))
# Загрузка numpy
import numpy
print('numpy: {}'.format(numpy.__version__))
# Загрузка matplotlib
import matplotlib
print('matplotlib: {}'.format(matplotlib.__version__))
# Загрузка pandas
import pandas
print('pandas: {}'.format(pandas.__version__))
# Загрукзка scikit-learn
import sklearn
print('sklearn: {}'.format(sklearn.__version__))Вот пример вывода:
Python: 3.7.0 (default, Jun 28 2018, 08:04:48) [MSC v.1912 64 bit (AMD64)]
scipy: 1.1.0
numpy: 1.15.1
matplotlib: 2.2.3
pandas: 0.23.4
sklearn: 0.19.2В идеале, ваши версии должны соответствовать или быть более поздними. API библиотек не меняются быстро, так что не не стоит переживать, если ваша версии другие. Все в этом урове, скорее всего, все еще будет работать для вас.
Если же выдает ошибку, рекомендуем обновить версионность системы. Если вы не можете запустить скрипт выше, вы не сможете пройти урок.
2. Загрузите данные
Мы будем использовать датасет цветов ирисов Фишера. Этот датасет известен тем, что он используется практически всеми в качестве "hello world" примера в машинном обучении и статистике.
Набор данных содержит 150 наблюдений за цветами ириса. В датасете есть четыре колонки измерений цветов в сантиметрах. Пятая колонна является видом наблюдаемого цветка.
Все наблюдаемые цветы принадлежат к одному из трех видов. Узнать больше об этом датасете можно в Википедия.
На этом этапе мы загрузим данные из URL-адреса в CSV файл.
2.1 Импорт библиотек
Во-первых, давайте импортировать все модули, функции и объекты, которые мы планируем использовать в этом уроке.
# Загрузка библиотек
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVCВсе должно загружаться без ошибок. Если у вас есть ошибка, остановитесь. Перед продолжением необходима рабочая среда SciPy. Посмотрите совет выше о настройке вашей среды.
2.2 Загрузка датасета
Мы можем загрузить данные непосредственно из репозитория машинного обучения UCI.
Мы используем модуль pandas для загрузки данных. Мы также будем использовать pandas чтобы исследовать данные как целей описательной статистики, так для визуализации данных.
Обратите внимание, что при загрузке данных мы указываем имена каждого столбца. Это поможет позже, когда мы будем исследовать данные.
# Загрузка датасета
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)Датасет должен загрузиться без происшествий.
Если у вас есть проблемы с сетью, вы можете скачать файл iris.csv в рабочую директорию и загрузить его с помощью того же метода, изменив URL на локальное имя файла.
3. Анализ датасета
Теперь пришло время взглянуть на данные более детально. На этом этапе мы погрузимся в анализ данные несколькими способами:
- Размерность датасета
- Просмотр среза данных
- Статистическая сводка атрибутов
- Разбивка данных по атрибуту класса.
Не волнуйтесь, каждый взгляд на данные является одной командой. Это полезные команды, которые можно использовать снова и снова в будущих проектах.
3.1 Размерность датасета
Мы можем получить быстрое представление о том, сколько экземпляров (строк) и сколько атрибутов (столбцов) содержится в датасете с помощью метода shape.
# shape
print(dataset.shape)Вы должны увидеть 150 экземпляров и 5 атрибутов:
(150, 5)3.2 Просмотр среза данных
Исследовании данных, стоит сразу в них заглянуть, для этого есть метод head()
# Срез данных head
print(dataset.head(20))Это должно вывести первые 20 строк датасета.
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa3.3 Статистическая сводка
Давайте взглянем теперь на статистическое резюме каждого атрибута. Статистическая сводка включает в себя количество экземпляров, их среднее, мин и макс значения, а также некоторые процентили.
# Стастические сводка методом describe
print(dataset.describe())
Мы видим, что все численные значения имеют одинаковую шкалу (сантиметры) и аналогичные диапазоны от 0 до 8 сантиметров.
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.5000003.4 Распределение классов
Давайте теперь рассмотрим количество экземпляров (строк), которые принадлежат к каждому классу. Мы можем рассматривать это как абсолютный счет.
# Распределение по атрибуту class
print(dataset.groupby('class').size())Мы видим, что каждый класс имеет одинаковое количество экземпляров (50 или 33% от датасета).
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
dtype: int643.5 Резюме загрузки датасета
На будущее мы можем объединить все предыдущие элементы вместе в один скрипт..
# Загрузка библиотек
from pandas import read_csv
# Загрузка датасета
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# shape
print(dataset.shape)
# Срез данных head
print(dataset.head(20))
# Стастические сводка методом describe
print(dataset.describe())
# Распределение по атрибуту class
print(dataset.groupby('class').size())4. Визуализация данных
Теперь когда у нас есть базовое представление о данных, давайте расширим его с помощью визуализаций.
Мы рассмотрим два типа графиков:
- Одномерные (Univariate) графики, чтобы лучше понять каждый атрибут.
- Многомерные (Multivariate) графики, чтобы лучше понять взаимосвязь между атрибутами.
4.1 Одномерные графики
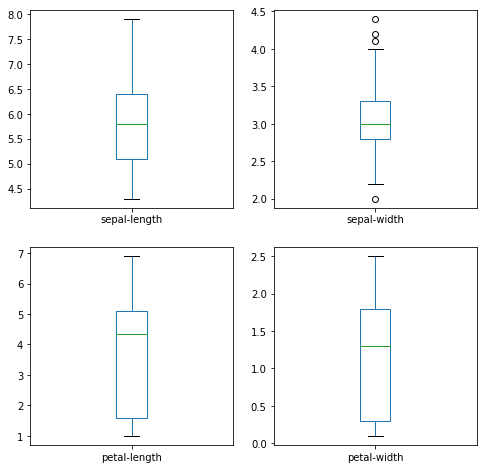
Начнем с некоторых одномерных графиков, то есть графики каждой отдельной переменной. Учитывая, что входные переменные являются числовыми, мы можем создавать диаграмма размаха (или "ящик с усами", по-английски "box and whiskers diagram") каждого из них.
# Диаграмма размаха
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
pyplot.show()Это дает нам более четкое представление о распределении атрибутов на входе.
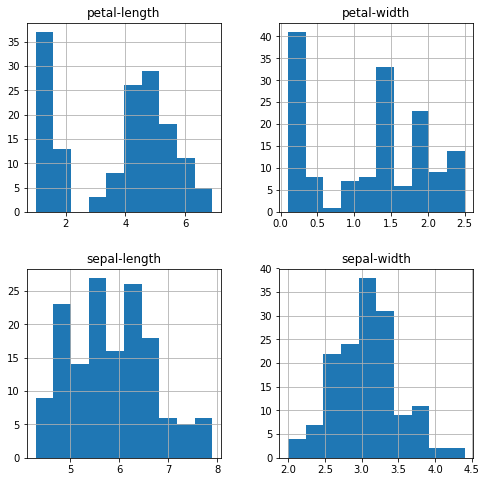
Мы также можем создать гистограмму входных данных каждой переменной, чтобы получить представление о распределении.
# Гистограмма распределения атрибутов датасета
dataset.hist()
pyplot.show()Из графиков видно, что две из входных переменных имеют около гауссово (нормальное) распределение. Это полезно отметить, поскольку мы можем использовать алгоритмы, которые могут использовать это предположение.
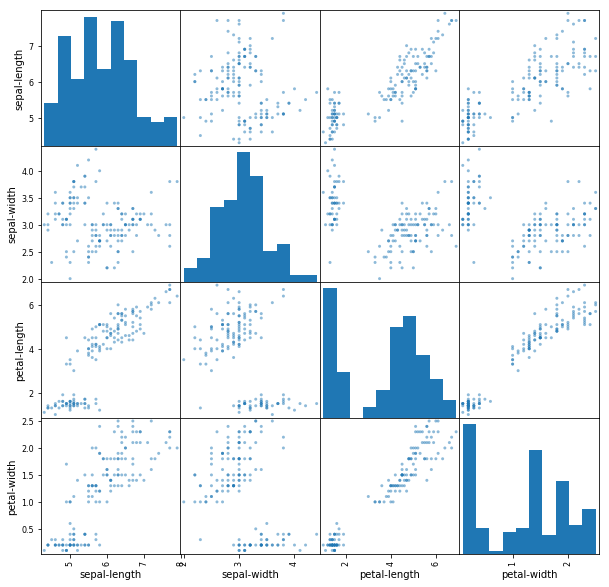
4.2 Многомерные графики
Теперь мы можем посмотреть на взаимодействия между переменными.
Во-первых, давайте посмотрим на диаграммы рассеяния всех пар атрибутов. Это может быть полезно для выявления структурированных взаимосвязей между входными переменными.
#Матрица диаграмм рассеяния
scatter_matrix(dataset)
pyplot.show()Обратите внимание на диагональ некоторых пар атрибутов. Это говорит о высокой корреляции и предсказуемой взаимосвязи.
4.3 Резюме визуализации данных
Для справки мы можем связать все предыдущие элементы вместе в один скрипт. Полный пример приведен ниже.
# Загрузка библиотек
from pandas import read_csv
# Загрузка датасета
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# Диаграмма размаха
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
pyplot.show()
# Гистограмма распределения атрибутов датасета
dataset.hist()
pyplot.show()
#Матрица диаграмм рассеяния
scatter_matrix(dataset)
pyplot.show()5. Оценка алгоритмов
Теперь пришло время создать некоторые модели данных и оценить их точность на контрольных данных.
Вот что мы собираемся охватить в этом шаге:
- Отделим обучающая выборка от контрольной (тестовой) выборке.
- Настройка 10-кратной кросс-валидации
- Построим несколько различных моделей для прогнозирования класса цветка из измерений цветов
- Выберем лучшую модель.
5.1 Создание контрольной выборки
Мы должны знать, что модель, которую мы создали, хороша.
Позже мы будем использовать статистические методы для оценки точности моделей. Мы также хотим получить более конкретную оценку точности наилучшей модели на контрольных данных, оценив ее по фактических контрольным данным.
То есть, мы собираемся удержать некоторые данные, на которых алгоритмы не будут обучаться, и мы будем использовать эти данные, чтобы получить второе и независимое представление о том, насколько точной может быть лучшая модель на самом деле.
Разделим загруженный датасет на два:
- 80% данных мы будем использовать для обучения, оценки и выбора лучшей среди наших моделей
- 20% данных, что мы будем использовать в качестве контрольного теста качества полученных моделей
# Разделение датасета на обучающую и контрольную выборки
array = dataset.values
# Выбор первых 4-х столбцов
X = array[:,0:4]
# Выбор 5-го столбца
y = array[:,4]
# Разделение X и y на обучающую и контрольную выборки
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)Теперь у вас есть обучающиеся данные в X_train и Y_train для подготовки моделей и контрольная выборка X_validation и Y_validation, которые мы можем использовать позже.
Обратите внимание, что мы использовали срез в Python для выбора столбцов в массиве NumPy.
5.2 Тестирование проверки
Для оценки точности модели мы будем использовать стратифицированную 10-кратную кросс-валидацию.
Это разделит наш датасет на 10 частей, обучающийся на 9 частях и 1 тестовой проверке и будет повторять обучение на всех комбинаций из выборок train-test.
Стратифицированная означает, что каждый прогон по выборке данных будет стремиться иметь такое же распределение примера по классу, как это существует во всем наборе обучаемых данных.
Для получения дополнительной информации о том как работает метод k-fold кросс-валидации можно посмотреть по ссылке.
Мы устанавливаем случайное затравку через random_state аргумент на фиксированное число, чтобы гарантировать, что каждый алгоритм оценивается на тех же выборках обучающихся данных. Конкретные случайные затравки не имеет значения.
Мы используем метрику «acccuracy» для оценки моделей.
Это соотношение числа правильно предсказанных экземпляров, разделенных на общее количество экземпляров в наборе данных, умноженном на 100, чтобы дать процент (например, точность 95%). Мы будем использовать оценочную переменную, когда мы будем запускать сборку и оценивать каждую модель.
5.3 Строим модели машинного обучения
Мы не знаем, какие алгоритмы будет хороши для этой задачи или какие конфигурации их использовать.
Все что увидела выше, что некоторые классы частично линейно зависят в некоторых измерениях, поэтому в целом ожидаем хорошие результаты.
Давайте протестируем 6 различных алгоритмов:
- Логистическая регрессия или логит-модель (LR)
- Линейный дискриминантный анализ (LDA)
- Метод k-ближайших соседей (KNN)
- Классификация и регрессия с помощью деревьев (CART)
- Наивный байесовский классификатор (NB)
- Метод опорных векторов (SVM)
Здесь приведена смесь простых линейных (LR и LDA), нелинейных (KNN, CART, NB и SVM) алгоритмов.
Давайте построим и оценим наши модели:
# Загружаем алгоритмы модели
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# оцениваем модель на каждой итерации
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))5.4 Выбираем модель
Теперь у нас есть 6 моделей и оценки точности каждой из них. Мы должны сравнить модели друг с другом и выбрать наиболее точные.
Запустив приведенный выше пример, мы получим следующие необработанные результаты:
LR: 0.955909 (0.044337)
LDA: 0.975641 (0.037246)
KNN: 0.950524 (0.040563)
CART: 0.951166 (0.052812)
NB: 0.951166 (0.052812)
SVM: 0.983333 (0.033333)Обратите внимание, что ваши результаты могут немного варьироваться, учитывая стохастический характер алгоритмов обучения.
Как интерпретировать полученные значения качества моделей?
В этом случае, мы видим, что это выглядит как метод опорных векторов (SVM) имеет самый большой расчет точности около 0,98 или 98%.
Мы также можем создать график результатов оценки модели и сравнить расхождение средней точность каждой модели. Существует разбор показателей точности для каждого алгоритма, потому что каждый алгоритм был оценен 10 раз (в рамках 10-кратной кросс-валидации).
Хороший способ сравнить результаты для каждого алгоритма заключается в создании диаграмме размаха атрибутов выходных данных и их усов для каждого распределения и сравнения распределений.
# Сравниванием алгоритмы
pyplot.boxplot(results, labels=names)
pyplot.title('Algorithm Comparison')
pyplot.show()Мы видим, что ящики и усы участков в верхней части диапазона достигают 100% точности, а некоторые находятся в районе 85% точности.
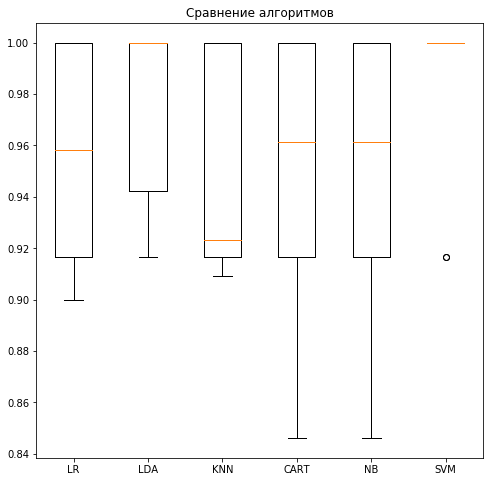
5.5 Резюме оценки алгоритмов
Для справки мы можем связать все предыдущие элементы вместе в один скрипт. Полный пример приведен ниже.
# Загрузка библиотек
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# Загрузка датасета
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# Разделение датасета на обучающую и контрольную выборки
array = dataset.values
# Выбор первых 4-х столбцов
X = array[:,0:4]
# Выбор 5-го столбца
y = array[:,4]
# Разделение X и y на обучающую и контрольную выборки
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
# Загружаем алгоритмы моделей
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# оцениваем модель на каждой итерации
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
# Сравниванием алгоритмы
pyplot.boxplot(results, labels=names)
pyplot.title('Algorithm Comparison')
pyplot.show()6. Прогнозирование данных
Прежде чем что-либо прогнозировать необходимо выбрать алгоритм для прогнозирования. По результатам оценки моделей предыдущего раздела мы выбрали модель SVM как наиболее точную. Мы будем использовать эту модель в качестве нашей конечной модели.
Теперь мы хотим получить представление о точности модели на нашей контрольной выборке данных.
Это даст нам независимую окончательную проверку точности лучшей модели. Полезно сохранить контрольную выборку для случаев когда была допущена ошибки в процессе обучения, такая как переобучение или утечка данных. Обе эти проблемы могут привести к чрезмерно оптимистичному результату.
6.1 Создаем прогноз
Мы можем протестировать модель на всей выборке обучаемых данных и сделать прогноз на контрольной выборке.
# Создаем прогноз на контрольной выборке
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
predictions = model.predict(X_validation)6.2 Оцениваем прогноз
Мы можем оценить прогноз, сравнив его с ожидаемым результатом контрольной выборки, а затем вычислить точность классификации, а также матрицу ошибок и отчет о классификации.
# Оцениваем прогноз
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))Мы видим, что точность 0,966 или около 96% на контрольной выборке.
Матрица ошибок дает представление об одной допущенной ошибке (сумма недиагональных значений).
Наконец, отчет о классификации предусматривает разбивку каждого класса по точности (precision), полнота (recall), f1-оценка, показывающим отличные результаты (при этом контрольная выборка была небольшая, всего 30 значений).
0.9666666666666667
[[11 0 0]
[ 0 12 1]
[ 0 0 6]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 0.92 0.96 13
Iris-virginica 0.86 1.00 0.92 6
avg / total 0.97 0.97 0.97 30
6.3 Резюме прогнозирование данных
Для справки мы можем связать все предыдущие элементы вместе в один скрипт. Полный пример приведен ниже.
# Загрузка библиотек
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
# Загрузка датасета
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# Разделение датасета на обучающую и контрольную выборки
array = dataset.values
# Выбор первых 4-х столбцов
X = array[:,0:4]
# Выбор 5-го столбца
y = array[:,4]
# Разделение X и y на обучающую и контрольную выборки
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=1)
# Создаем прогноз на контрольной выборке
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
predictions = model.predict(X_validation)
# Оцениваем прогноз
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))Машинное обучение в Python это не сложно
Проработайте примеры из урока, это не займет дольше 10-15 минут.
Вам не обязательно сразу все понимать. Ваша цель состоит в том, чтобы запустить ряд скриптов описанных в уроке и получить конечный результат. Вам не нужно понимать все при первом проходе. Записывайте свои вопросы параллельно с тем как пишите код. Рекомендуем использовать справку ("FunctionName") в Python чтобы разобраться глубже во всех функциях, которые вы используете.
Вам не нужно знать, как работают алгоритмы. Важно знать об ограничениях и о том, как настроить алгоритмы машинного обучения. Более подробное узнать о конкретных алгоритмах можно и позже. Вы должны постепенно накапливать знания о работе алгоритмы. Сегодня, начните с того что поймете как его использовать в Python.
Вам не нужно быть программистом Python. Синтаксис языка Python может быть интуитивно понятным, даже если вы новичок в нем. Как и на других языках, сосредоточьтесь на вызовах функций (например,function()) и назначениях (например, a = "b"). Если вы являетесь разработчиком, вы итак уже знаете, как подобрать основы языка очень быстро.
Вам не нужно быть экспертом по машинного обучению. Вы можете узнать о преимуществах и ограничениях различных алгоритмов гораздо позже, и есть много информации в интернете, о более глубинных тонкостях алгоритмов и этапах проекта машинного обучения и важности оценки точности с помощью перекрестной валидации.
Итого
Вы сделали свой первый мини-проект по машинному обучению в Python.
Вы наверняка обнаружили, что после завершения даже небольшого проекта от загрузки данных до прогнозирования — вы уже намного сильнее продвинулись.
Какие могут быть следующие шаги по изучению машинного обучения?
Мы не освещали все этапы проекта машинного обучения, потому что это ваш первый проект, и нам нужно сосредоточиться на ключевых этапах. А именно, загрузке данных, анализе данных, оценка некоторых алгоритмов и прогнозировании данных. В других уроках мы рассмотрим другие аспекты машинного обучения по подготовке данных и улучшению результатов.

